Introduction
The akaBot Vision API allows you to programmatically access and manage your organization's data and account information.
In this document, you will find an introduction to the API usage from a developer perspective and a reference to all the API objects and methods.
How does the API in akaBot Vision work?
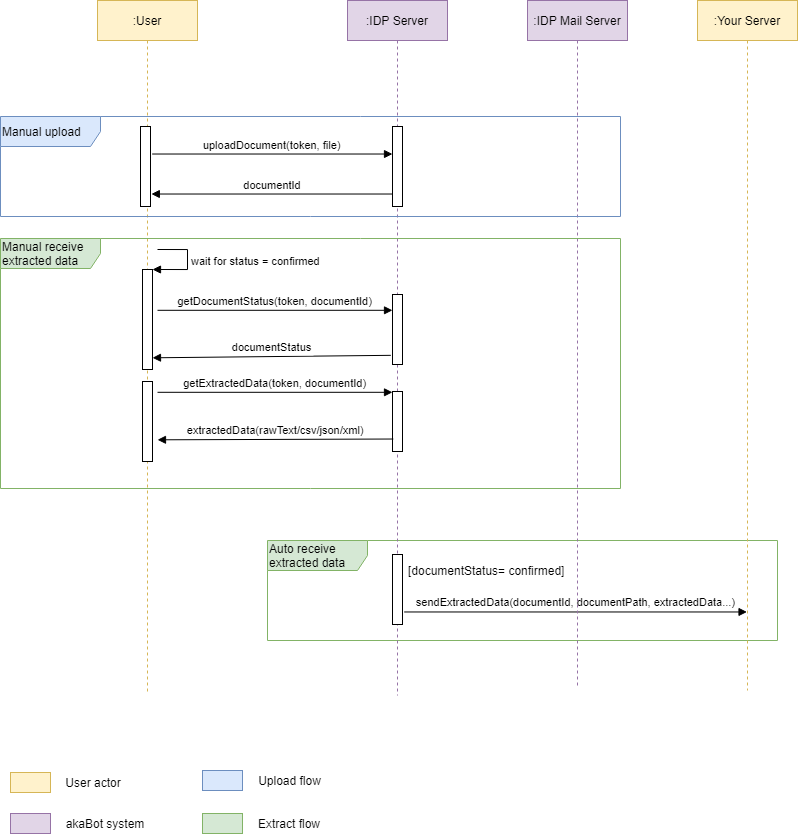
a. Import Document
The user has to log in to akaBot Vision to get token in the API Key in the Account section below the user's profile section first. 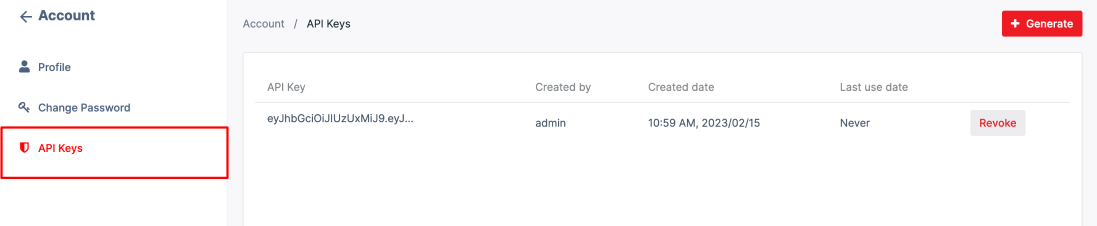
Then user can upload documents manually by calling API Import Document and sending request information (token and files need to be uploaded) to IDP Server then IDP Server will respond the documentIds and document status "Importing" to user. It might take IDP Server 2-3 minutes to process document depending on the document's size.
b. Get Document Status
After the processing time, the user kindly re-checks the document's status by calling API Get Document Status and the request information is documentId which has been responded to via API Import Document
- If the document has the status "Confirmed", it means this document is processed successfully and the user can export data via calling API Export Document with input parameters (Id and exportType)

- If the document has the status "Rejected", it means that IDP detected this document not to be an invoice and then rejected it.

- If the document has the"Splitted" status and splittedDocs is not empty, it means this document has multiple pages, and IDP automatically split into child documents. Users can map split-document by using the parent id
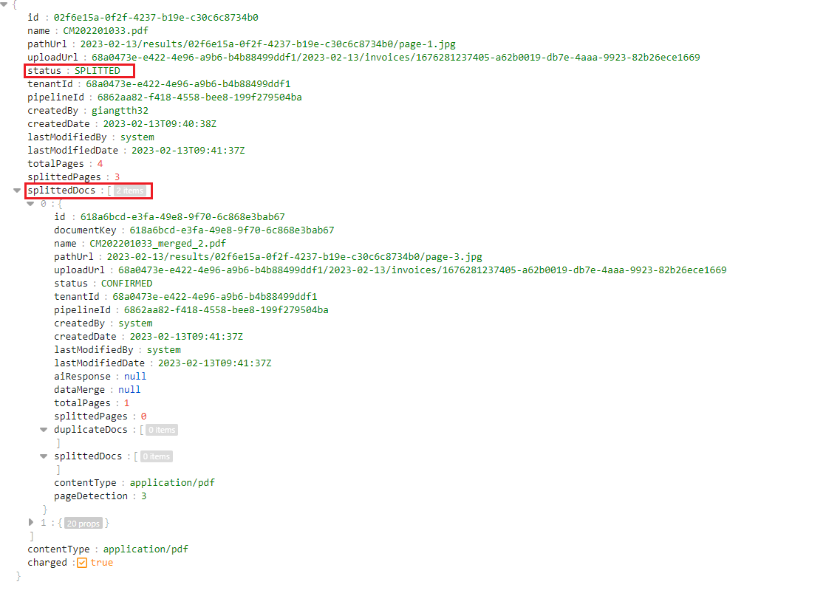
- At this time, the user can check the status of the child documents by calling API Get Document Status for documentIds that have been responded to in splittedDocs and export the "Confirmed" documents in splittedDocs by calling API Export Document
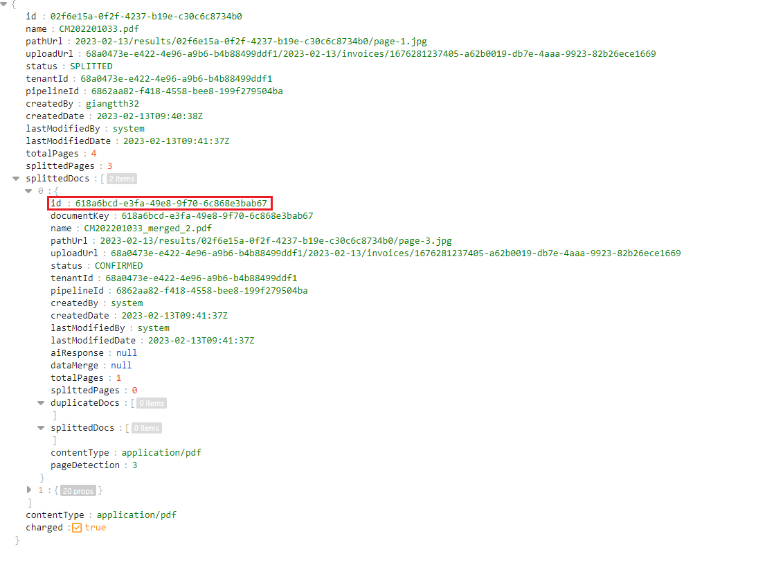
- At this time, the user can check the status of the child documents by calling API Get Document Status for documentIds that have been responded to in splittedDocs and export the "Confirmed" documents in splittedDocs by calling API Export Document
- If the document has the "To-review" status, it means that the user needs to review documents then change it to "Confirmed" status by API Update Document Status before exporting data
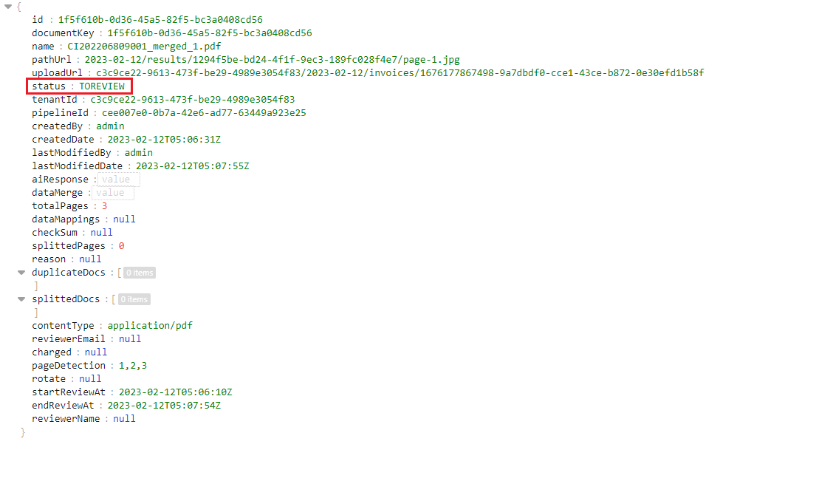
c. Get Documents
If users want to get a list of all documents with a specific status, user can call API Get Documents
d. Export Documents
The user needs to wait for the document to be changed to the "Confirmed" status and get the extracted data information by calling the API Export Document to IDP Server with the input parameters (token, documentId that need to be extracted and file format that user wants to export), then the API Export Document will respond to the user the extracted data in the chose format.
API Details
1. Import Document
- Purposes: Documents can be imported into akaBot Vision using the REST API. Supported file formats are PDF, PNG, JPEG.
- URL: {serverEndpoint}/api/uploadFile/{pipelineId}
- Content-Type: multipart/form-data
- Method: POST
- Request header: Authorization: Bearer {apiKey}
- Input body:
| Attribute | Type | Description | Required |
| pipelineId | string | Pipeline’s id | Yes |
| files | Form-data | List documents that want to be uploaded | Yes |
- Response:
If success, will return code 200 and response is Document model array
If fail, will return error code and message code as below
| Responses code | Description |
| 200 | OK |
| 201 | Created |
| 401 | Unauthorized |
| 403 | Forbidden |
| 404 | Not found |
Example Response:
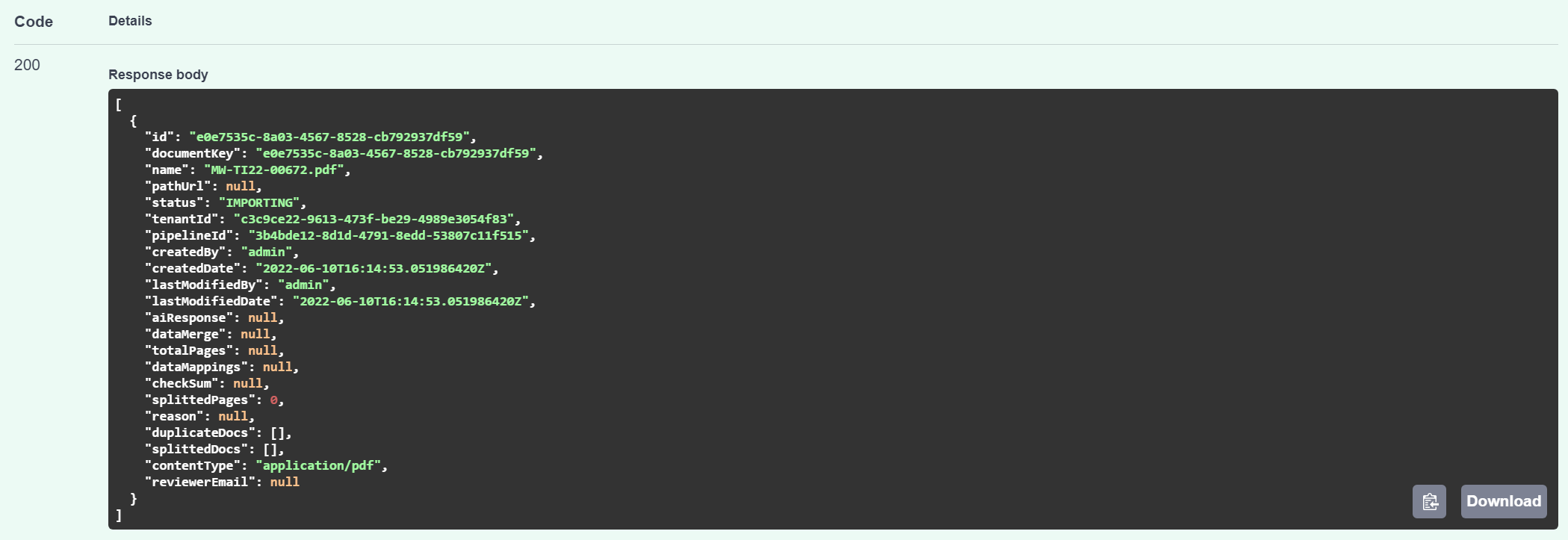
2. Export Document
- Purposes: Documents after being confirmed can be exported to csv,json,xlxs,xml file via API export document
- URL: {serverEndpoint}/api/export-documents/{id}?exportType={exportType}
- Content-Type: application/json
- Method: GET
- Request header: Authorization: Bearer {apiKey}
- Input parameters:
| Attribute | Type | Description | Required |
| id | string | Document id want export data | Yes |
| exportType | string | File format that user wanted to export
| Yes |
- Output
- If success, will return code 200 and file with input type
- If fail, will return error code and message code as below
| Responses code | Description |
| 200 | OK |
| 401 | Unauthorized |
| 403 | Forbidden |
| 404 | Not found |
Example Response:
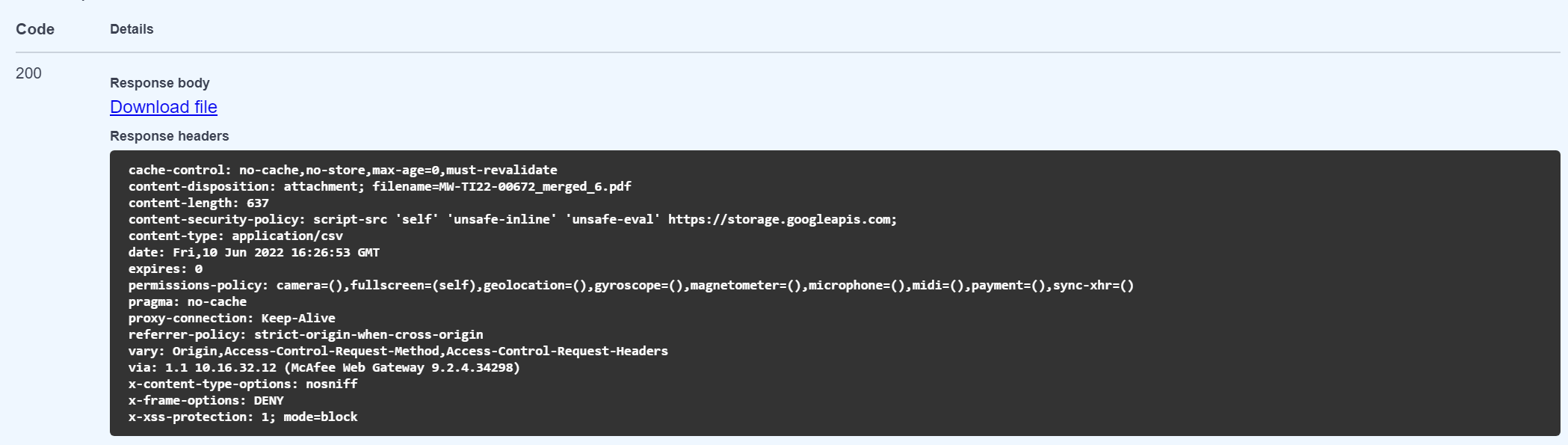
3. Get Documents
- Purposes: Can get list documents of specific pipeline with specific status (IMPORTING,TOREVIEW,CONFIRMED,EXPORTED,DELETED,REJECTED). If user do not send status to API, API will respond the list of documents with all statuses
- URL: {serverEndpoint}/api/documents?page={page}&size={size}&status={status}&pipelineId={pipelineId}&documentName={documentName}&dateFrom={dateFrom}&dateTo={dateTo}&sort=createdDate,desc
- Content-Type: application/json
- Method: GET
- Request header: Authorization: Bearer {apiKey}
- Input parameters:
| Attribute | Type | Description | Required |
| page | integer | Page number of the requested page | No |
| size | integer | Size of a page | No |
| sort | string | Sorting criteria in the format: property(,asc|desc). Default sort order is ascending. | No |
| status | string | Documents’ status (IMPORTING, TOREVIEW, CONFIRMED, EXPORTED, DELETED, REJECTED) | No |
| pipelineId | string | Pipeline’s Id | Yes |
| documentName | string | Search for document names containing input values | No |
| dateFrom | integer | Sort document from date | No |
| dateTo | integer | Sort document to date | No |
- Output
If success, will return code 200 and response is Document model array
If fail, will return error code and message code as below
| Responses code | Description |
| 200 | OK |
| 401 | Unauthorized |
| 403 | Forbidden |
| 404 | Not found |
Example Response:
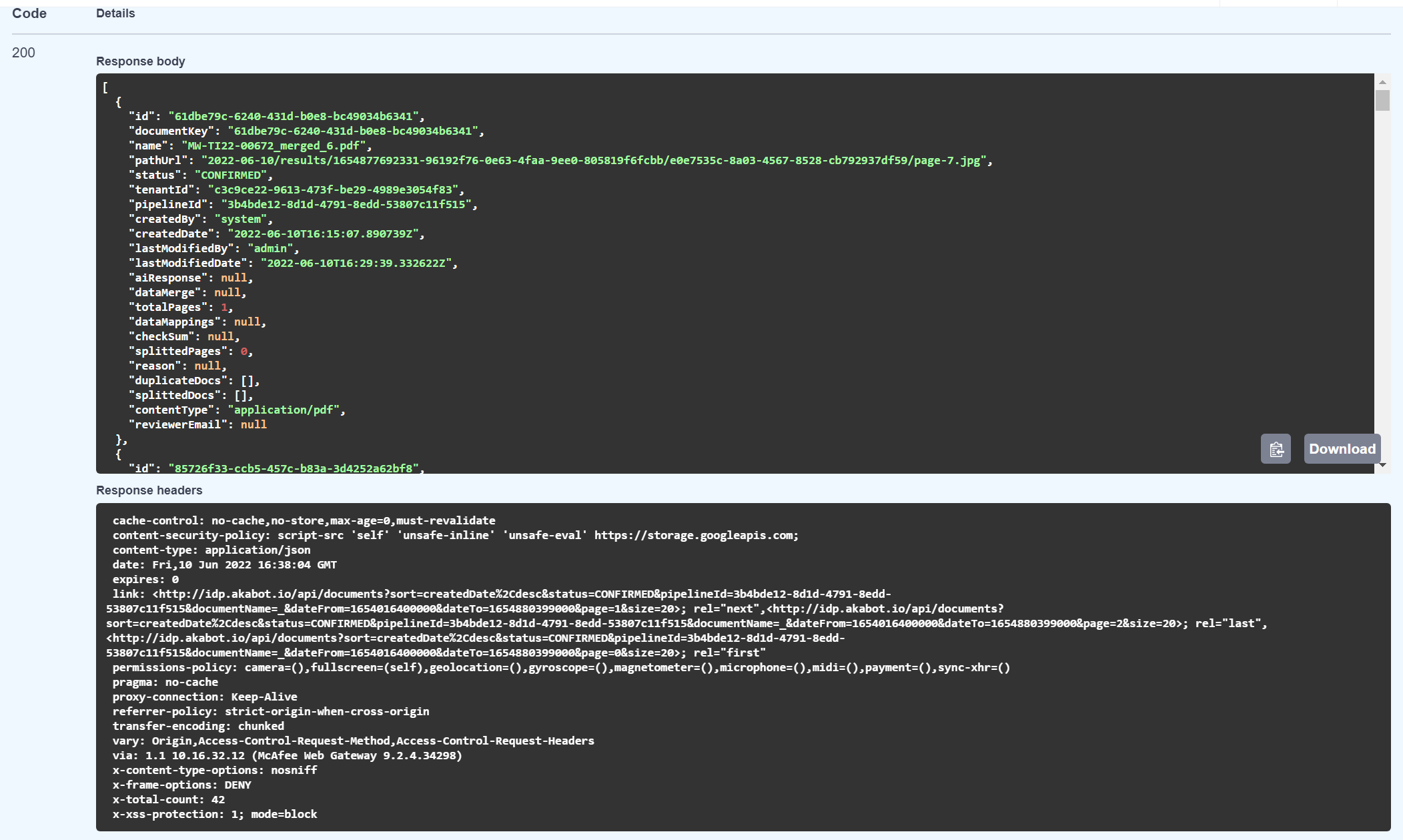
4. Update Document Status
- Purposes: User can change document status via API update document status
- URL: {serverEndpoint}/api/change-docs-status
- Content-Type: application/json
- Method: POST
- Request header: Authorization: Bearer {apiKey}
- Input body:
| Attribute | Type | Description | Required |
| docIds | String array | List document’s Id need to be updated status | Yes |
| statusChange | string | The status that documents will change to | Yes |
- Output
- If success, will return code 200
- If fail, will return error code and message code as below
| Responses code | Description |
| 200 | OK |
| 401 | Unauthorized |
| 403 | Forbidden |
| 404 | Not found |
Example Response:
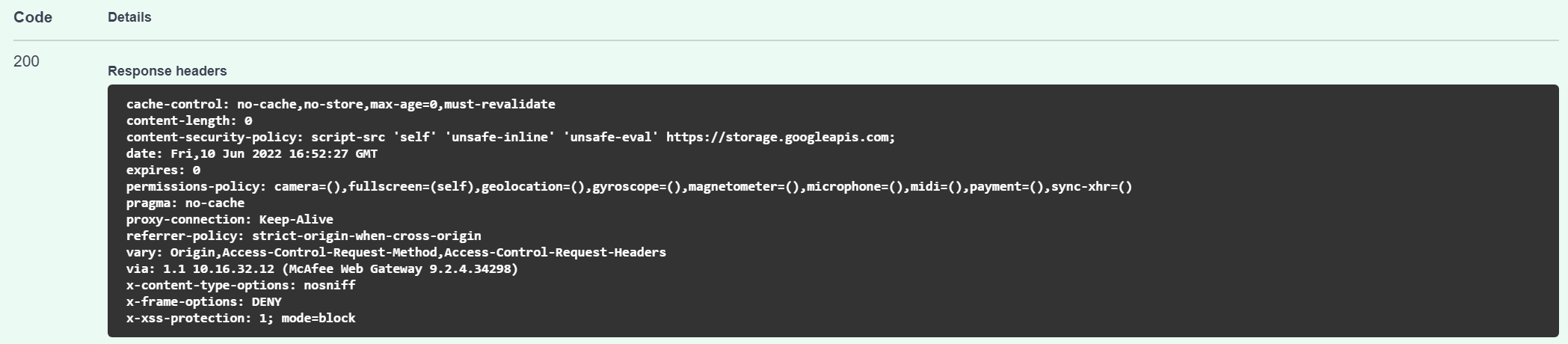
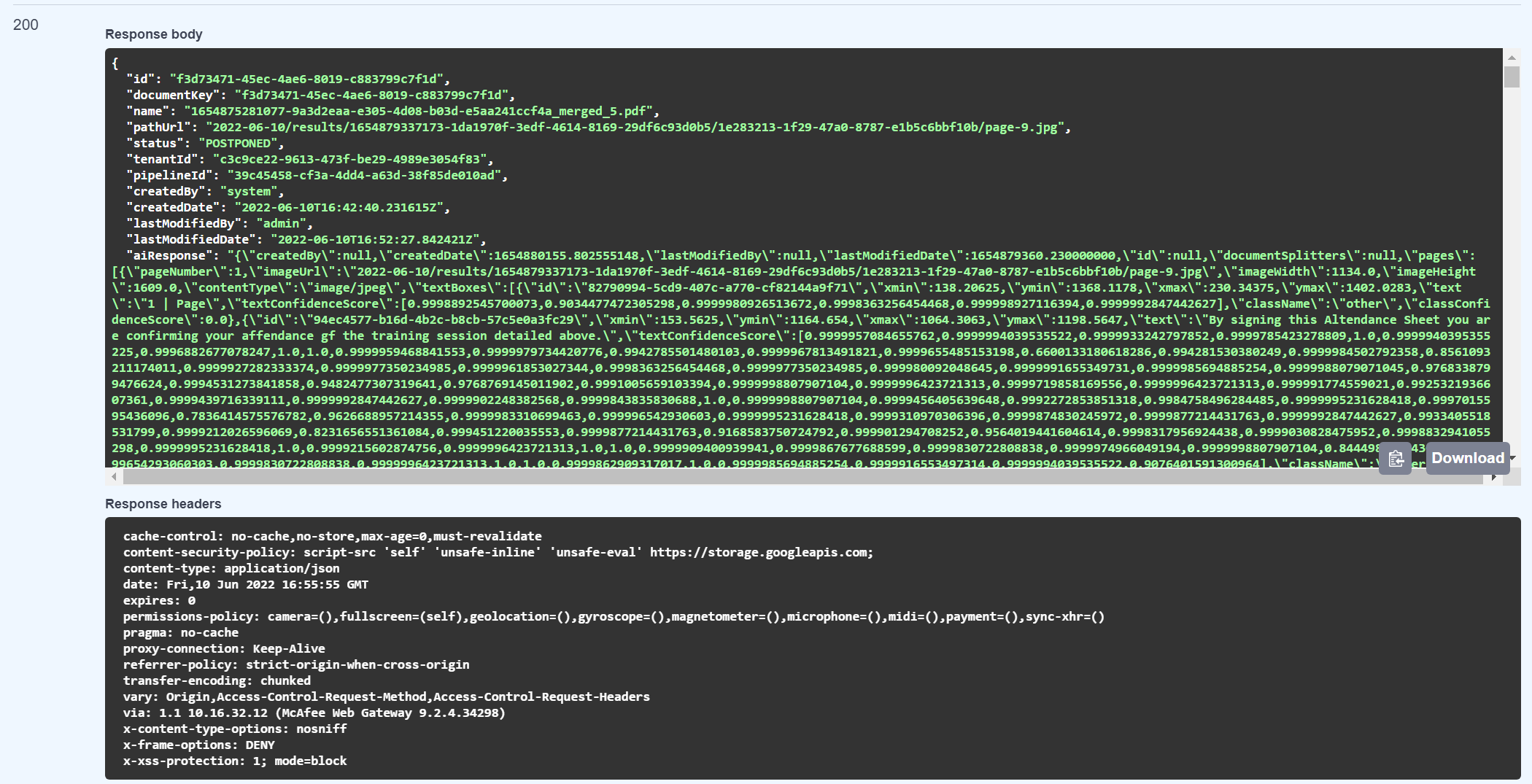
5. Get Document Status
- Purposes: Get document status
- URL: {serverEndpoint}/api/documents/{id}
- Content-Type: application/json
- Method: GET
- Request header: Authorization: Bearer {apiKey}
- Input parameters:
| Attribute | Type | Description | Required |
| id | string | Document Id want to get info | Yes |
- Output:
If success, will return code 200 and response is a Document model
If fail, will return error code and message code as below
| Responses code | Description |
| 200 | OK |
| 401 | Unauthorized |
| 403 | Forbidden |
| 404 | Not found |
Example Response:
Appendix
- Server endpoint: https://idp.akabot.com/ or http://idp.akabot.io
- Get API Key:
Step 1: Go to {serverEndpoint} /account/api-keys
Step 2: Copy key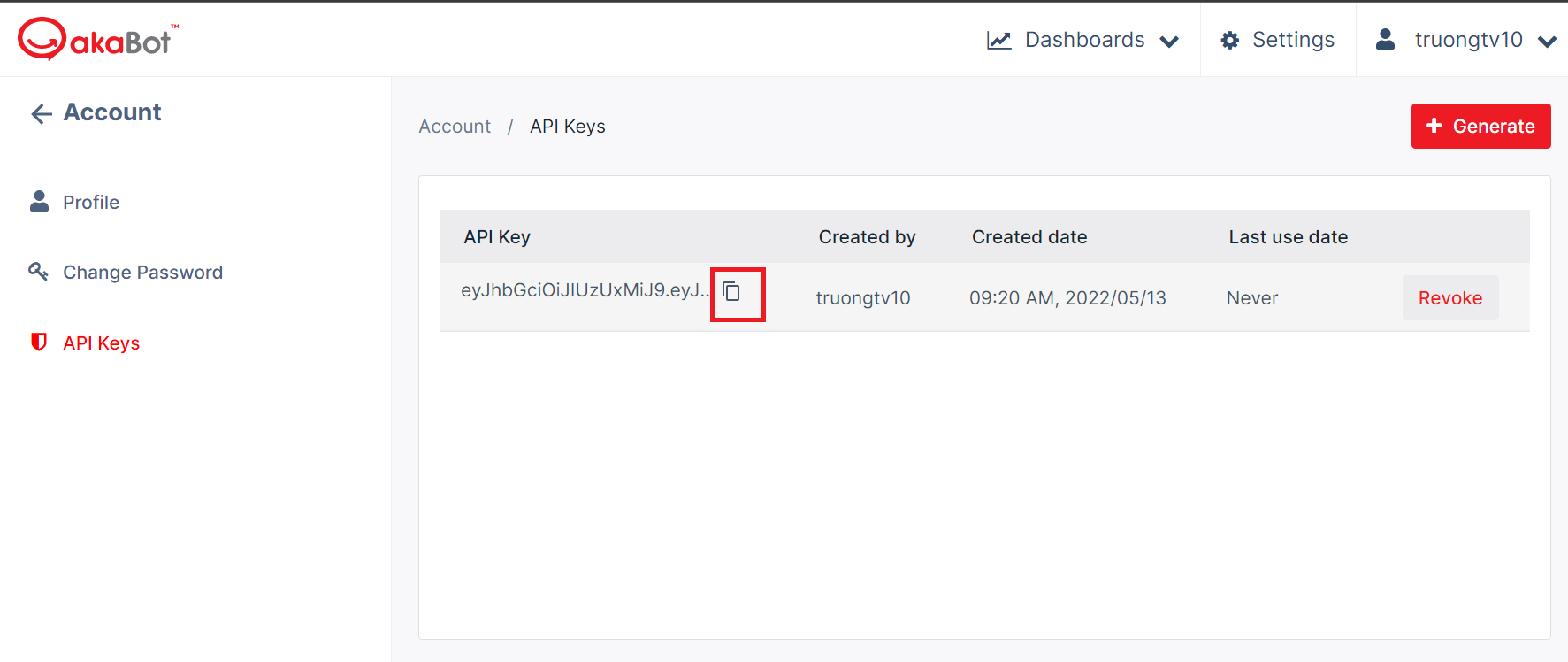
- Status is support: akaBot Docs
- Document model type:
| Attribute | Type | Description |
| aiResponse | string | Result get from AI |
| checkSum | string | List documents that want to be uploaded |
| contentType | string | Uploaded document’s format |
| createBy | string | Person who upload documents |
| createDate | string | Date upload document |
| dataMappings | array | |
| dataMerge | string | Mapping results between field to capture and AI’s results |
| documentKey | string | Document’s id |
| duplicateDocs | array | List documents are duplicated to recently uploaded documents Id: Duplicate document’s id Name: Duplicate document’s name Status: Duplicate document’s status
|
| id | Document’s id | |
| lastModifiedBy | string | Person who last modified the document |
| lastModifiedDate | Datetime | Date when document was last modified |
| name | string | Document’s name |
| pathUrl | string | Document’s URL |
| pipelineId | string | Pipeline’s id |
| reason | string | Reason for rejecting documents |
| reviewerEmail | string | Email who review documents |
| splittedDocs | array | List documents after being splitted |
| splitedPages | number | Number of document’s pages after being splitted |
| status | string | Document’s status |
| tenantId | string | Tenant’s Id |
| totalPages | string | Total pages of documents |