Each Pipeline defines the structure of Data fields that akaBot Vision extracts.
Description
When editing this structure you have two options:
- Use pre-trained Data fields – AkaBot Vision’s Generic AI engine has been pre-trained to recognize specific Data fields and enables you to start extracting data without any additional training for the AI.
- Define Custom data fields and train the Dedicated AI engine to automatically extract them. (This option will be available in Q3/2022)
How to customize data extraction with pre-trained Data fields
Using pre-trained Data fields is simple. This function works out of the box and is easy to set up.
After you log in to akaBot Vision, go to the Settings screen by clicking “Settings” button in the upper right corner.

- Select the pipeline you want to configure.
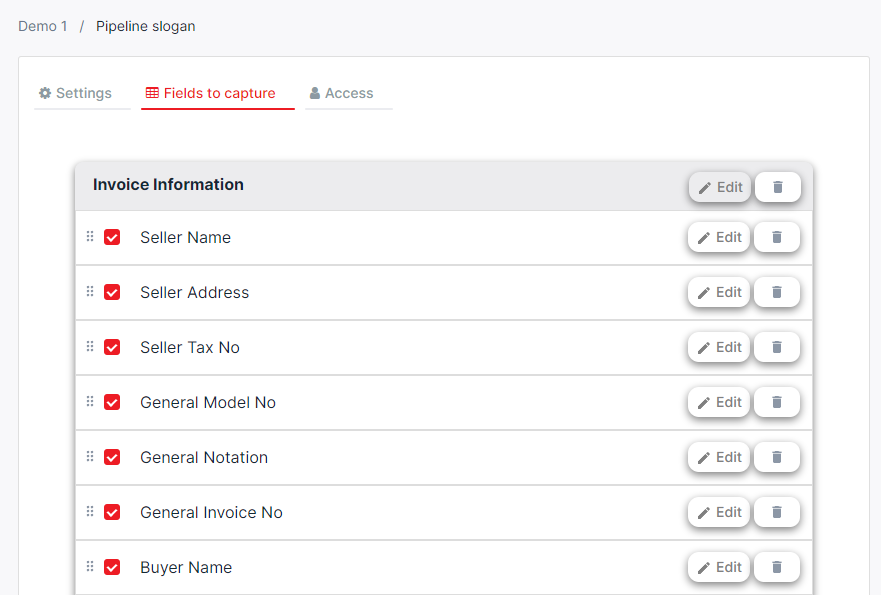
- This opens a pipeline settings screen where you can open the “Fields to capture” tab.
- In this tab, you can select and deselect fields according to their relevance to the documents you are processing.
- When you are done, click “Save” to store your settings.